
I’ve been playing with calculating the entropy of a toy system used to illustrate the connection between “disorder” and entropy. (See Entropy 101 and Entropy 102.) I needed to calculate the minimum number of moves required to sort a disordered collection, but that turns out to be an NP problem (no doubt related to Traveling Salesman).
The illustration bridges Boltzmann and Shannon entropy, which got me playing around with the latter, and that led to some practical results. This article describes the code I used mainly as an excuse to try embedding my own colorized source code blocks.
I’m not going to get into entropy here (I’ve posted about it plenty elsewhere). What matters is that this code involves Shannon entropy, not Boltzmann entropy. They’re closely related but involve quite different domains and enough differences to make calling them the same thing ever so slightly questionable.
Regardless, rather than Boltzmann’s famous thermodynamic formula:

The code here uses Shannon’s version:

Which gives an answer in binary bits because of the log2 function. Using the log10 function gives a result in terms of decimal digits. The symbol density determines the log base (or vice versa).
Implementing the equation is very simple:
002|
003| def shannon_entropy (NP, PF, logbase=2):
004| “””Calculate the Shannon Entropy given PF(x).”””
005| # Generate probabilities…
006| probs = [PF(x) for x in range(NP)]
007| tprob = sum(probs) # expected to be 1.000
008| # Generate summation terms…
009| ents = [p*log(p,logbase) for p in probs]
010| ent = –sum(ents)
011| # Return all the generated data…
012| return (ent, ents, tprob, probs)
013|
014| def demo_shannon_entropy (n_patts=27):
015| probfunc = lambda x:1/float(n_patts)
016| ent,_,tp,_ = shannon_entropy(n_patts, probfunc)
017| print(ent)
018| print(tp)
019| print()
020|
It can be done in a single line lambda expression if one doesn’t mind calling the probability function twice:
002|
003| “””Calculate the Shannon Entropy given PF(x).”””
004| shannon_entropy = \
004| lambda N,P: –sum([P(x)*log2(P(x)) for x in range(N)])
005|
But I do, so first I generate a list of all the probabilities for each system micro-state (line #6). As a safety check, in the next line, I also generate a sum of those probabilities (something the one-liner can’t do). The expected sum is 1.000 (give or take a floating-point error).
Then I generate a list of summation terms (line #9), sum them to derive the entropy (line #10), and return the entropy, the total probability, and both lists. Most applications will only care about the entropy value, but the other data is available if wanted.
When run with the 27-pattern default, the demo prints:
4.754887502163471 0.9999999999999993
Telling us the entropy is ~4.755 bits and, as expected, the probabilities do sum to 1.000, give or take a floating-point error. The entropy value is the same as:
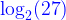
That’s because the probability function (line #15) assigns equal probability (1/NP) to all possible patterns. When all patterns are the same, the entropy is maximum and the same as the number of bits required to express all possible patterns. (If we had 32 patterns, the max entropy would be exactly 5.000 because five bits can express exactly 32 patterns.)
Note that if we change logbase to 10, then the demo prints:
1.4313637641589871 0.9999999999999993
Telling us the same 27-pattern system, when all patterns are equal, has an entropy of ~1.43 decimal digits. Setting logbase to other values results in different entropy values. The entropy just says how many symbols are required to express NP many values.
§
In a way, that’s it, everything else is an application of that calculation. But there are some interesting things we can do to explore its consequences.
Imagine we have a “tea” variable that can specify one of 27 types of tea. (Imagine a tiny dial with a pointer.) As just shown, when all 27 teas are equally likely, the dial could point to any of them, we say the variable has maximum entropy (of ~4.755 if we mean bits). This effectively means the variable is random — it has maximum surprise. Things get more interesting when we vary the pattern probabilities.
A very simple extension assigns a high probability to one pattern (tea) and a low probability to all others. We’re saying the tea dial is very likely to point to some given tea, and very unlikely to point to any other. In this simple case we’ll assign the same low probability to all other possible teas. Here’s some code:
002|
003| def demo_shannon_entropy (NB=5, p_of_x=None):
004| “””Shannon entropy for a specific P(X).”””
005| NP = pow(2,NB)
006| PF = (1.0/NP) if p_of_x is None else p_of_x
007| PX = randint(1, NP–1)
008| probs = lambda x:PF if x==PX else ((1.0–PF)/(NP–1))
009| ent,_,tprob,_ = shannon_entropy(NP, probs)
010| print()
011| print(‘NB=%d, NP=%d’ % (NB,NP))
012| print(‘P(PX)=PF=%.12f’ % PF)
013| print(‘tot-prob=%.12f’ % tprob)
014| print(‘entropy=%.12f’ % ent)
015| print()
016| return ent
017|
The sum of all probabilities must be 1.000, so the probability function must be normalized. That’s why the example above used 1/NP for each pattern’s probability. The sum is NP×(1/NP), which is obviously one. Here, normalization is ever so slightly trickier.
Firstly, the demo function takes NB (number of bits), rather than NP (number of patterns). For these demos we’ll use whole numbers of bits because fractional values, such as for 27 teas, don’t really change anything. The convenience is that in using whole bits, our maximum entropy is always the number of bits.
We do need NP, so line #5 calculates it. The next line sets PF to the input argument p_of_x (probability of X) if it was provided, otherwise uses the default 1/NP (which will result in maximum entropy). We set PX to some random pattern, and line #8 defines the probability function: return PF if the pattern matches PX otherwise return a low probability calculated as 1.0-PF divided among all other patterns.
When run with defaults, the demo prints:
NB=5, NP=32 P(PX)=PF=0.031250000000 tot-prob=1.000000000000 entropy=5.000000000000
As expected, the entropy is 5.00 and the probabilities sum to 1.00. The probability of the expected number is only 3.125% — or odds of exactly 1/32 for each pattern. Maximum entropy, maximum surprise.
But if we set p_of_x=0.99, it prints:
NB=5, NP=32 P(PX)=PF=0.990000000000 tot-prob=1.000000000000 entropy=0.130335099000
A much-reduced entropy value. There is a 99% probability the dial will point to the expected number, so there is very little surprise. We can take things even further by setting p_of_x=0.999999 — a near certainty of the expected answer:
NB=5, NP=32 P(PX)=PF=0.999999000000 tot-prob=1.000000000000 entropy=0.000026328459
Almost no surprise at all.
§
Looking at the way making one answer more likely changes the entropy naturally led me to charting the curve as entropy is reduced this way from maximum to some tiny value. (It approaches zero, but since log(0) is an invalid expression, it can never get there.)
Here’s some code:
002|
003| def demo_shannon_curve (NB=5):
004| “””Shannon Entropy curve for P(X).”””
005| extra = [0.999999, 0.9999999]
006| NP = pow(2,NB)
007| X = randint(1, NP–1)
008| print(‘NB=%d, NP=%d’ % (NB,NP))
009| print(‘X=%d’ % X)
010| print()
011| # P(X) goes from 1/NP thru (NP-1)/NP…
012| ps = [n/NP for n in range(1,NP)]
013| # Loop over probabilities for P(X)…
014| for ix,p in enumerate(ps+extra):
015| PF = lambda x:p if x==X else ((1.0–p)/(NP–1))
016| ent,_,tp,_ = shannon_entropy(NP, PF)
017| print(‘%4d: %.9f = %.12f (%.6f)’ % (1+ix, p, ent, tp))
018| print()
019|
It starts off like the demo above, but line #12 calculates a list of probabilities from 1/NP to (NP-1)/NP — which approaches, but doesn’t reach, 1.00. Two extra probabilities getting even closer to 1.00 get tacked on to get the curve closer to zero.
When run it prints a list:
1: 0.031250000 = 5.000000000000 (1.000000) 2: 0.062500000 = 4.981849107605 (1.000000) … … 32: 0.999999000 = 0.000026328459 (1.000000) 33: 0.999999900 = 0.000002965039 (1.000000)
I used a function like this to generate data I could make a chart with:
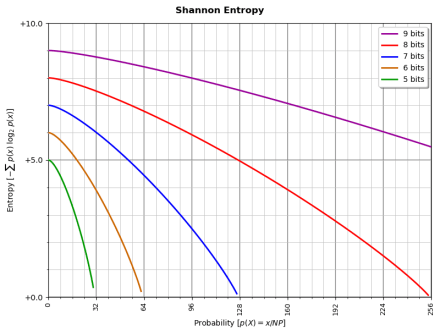
As you see, the entropy curve approaches zero. Mathematically it can’t get there, but conceptually, if the probability is 1.00, there’s no surprise in the answer (effectively, it’s already known) and the entropy is zero.
§
This post was mainly an excuse to see if inserting my HTML Python code would work (look like). I’ll leave you with a complete class you can use for your own explorations:
002|
003| def bit_cmp (x, y):
004| n = x ^ y
005| return sum([int(b) for b in bin(n)[2:]])
006|
007| def n_choose_k (nb, k):
008| “””nb!/k!(nb-k)!”””
009| if nb < k: return 0
010| return int(factorial(nb)/(factorial(k)*factorial(nb–k)))
011|
012| class entropy (object):
013| “””Shannon Entropy Calculator class.”””
014| def __init__ (self, nbr_of_bits):
015| self.nb = nbr_of_bits
016| self.np = pow(2,self.nb)
017| def pf (self, x):
018| “””Probability Function. (Override in subclass!)”””
019| return 1.0
020| def __call__ (self):
021| “””Generate and print results.”””
022| self.ns = [n_choose_k(self.nb,k) for k in range(self.nb+1)]
023| # Normalized Probability Factors…
024| self.fs = [self.pf(x) for x in range(self.nb+1)]
025| self.ts = [n*f for n,f in zip(self.ns,self.fs)]
026| self.tp = sum(self.ts)
027| self.ps = [f/self.tp for f in self.fs]
028| # Calculate Shannon entropy…
029| self.xs = [self.ps[bit_cmp(0,p)] for p in range(self.np)]
030| self.es = [x*log2(x) for x in self.xs]
031| self.ent = –sum(self.es)
032| self.tpx = sum(self.xs)
033| # Print results…
034| print(str(self))
035| print()
036| for ix,rcd in enumerate(zip(self.ns,self.fs,self.ts,self.ps)):
037| print(‘%2d:%6d %12.4e %12.4e %14.6e’ % ((ix,)+rcd))
038| print()
039| print(‘PF(EXP)=%.8f (tp=%.6f)’ % (self.ps[0], self.tp))
040| print(‘entropy=%.8f (tp=%.6f)’ % (self.ent, self.tpx))
041| print()
042| return self.ent
043| def __str__ (self):
044| return ‘#bits:%d, #patterns:%d’ % (self.nb, self.np)
045|
046| class entropy1 (entropy):
047| def __init__ (self, nbits, divisor):
048| super().__init__(nbits)
049| self.prob = 1.0/float(divisor if divisor else self.np)
050| def pf (self, x):
051| return self.prob
052|
053| class entropy2 (entropy):
054| def __init__ (self, nbits, probability):
055| super().__init__(nbits)
056| self.prob = 1.0/float(probability)
057| def pf (self, x):
058| return (1.0 if x==0 else self.prob)
059|
060| class entropy3 (entropy):
061| def __init__ (self, nbits, factor):
062| super().__init__(nbits)
063| self.fact = float(factor)
064| def pf (self, x):
065| return (1.0/pow(self.fact,x))
066|
067| def demo_entropy_class (NB=8):
068| e0 = entropy(NB)
069| e1 = entropy1(NB, 5.0)
070| e2 = entropy2(NB, 1e6)
071| e3 = entropy3(NB, 250)
072| e0()
073| e1()
074| e2()
075| e3()
076| return (e0,e1,e2,e3)
077|
I won’t explain it here unless someone expresses an interest.
Link: Zip file containing all code fragments used in this post.
Ø

I hate — really, really hate — the way the WordPress Reader strips formatting from my posts! I highly advise never using the WP Reader and always viewing blog posts on the website.
This post, for instance, Calculating Entropy (in Python)
I should probably document those entropy sub-classes…
I never expected this to become my most popular post!
By a considerable margin!
As of today, 2,395 page hits. The next most-viewed post only has 412! 😮
But no questions, so I guess it’s completely clear to everyone?
Thank you for the post, very interesting. I would like to ask you something because I can’t find much specific information. Have you had convergence problems with the maximum entropy? I am working on a system that evolves over time in a simulation and theoretically the entropy should maximize and become an asymptote, but there are many fluctuations. My question is whether floating point or any other element of Python 3 could be responsible for these fluctuations, since theoretically this shouldn’t happen.
Python floats are 64-bit floating point with only 15-16 decimal digits of precision, so, depending on what your math is doing, there can definitely be issues with series. Maximum entropy at any given time is just the log of the number of possible combinations of the system, so the issue may be in how you’re calculating that number.
Also, depending on your system, Shannon entropy might not be what you need. I would think that most systems focused on evolution usually deal with Boltzmann entropy.
Hello, thank you very much, according to what you told me I was verifying and you are right the problem is in the calculation not in the entropy, I will improve the process and I will insist with Shannon. Greetings.
Not sure if the comment was submitted, again good response helped me a lot.
Glad it worked out. (WordPress didn’t know who you were, so it put the message in a moderation queue. Unfortunately, it doesn’t provide any feedback, so the message seems to just vanish.)
Pingback: Friday Notes (Aug 30, 2024) | Logos con carne
Pingback: Friday Notes (Sep 27, 2024) | Logos con carne