
Tags
To ring in the new year, I thought I’d play around with an old friend from my earliest programming days, a random text generator. Back then (over 30 years ago), but a little bit always, a good way to practice programming is by working on small, relatively easy, but still fun, programs.
Simple games are common choice, but not the only one. (I’ve probably written a version of Mastermind in every programming language I know.) Another fun choice is various image or text generators (or processors). Random text generators, in particular, offer a range of complexity depending on your taste and time.
Let’s start with a very simple example:
002|
003| # Random character from ‘A’ to ‘Z’…
004| randchar = lambda: chr(ord(‘A’)+randint(0,25))
005|
006| def random_text_1 (size=12):
007| ”’Simple Random Text Generator.”’
008|
009| # Generate a random list of chars…
010| s = [randchar() for _ in range(min(24,size))]
011|
012| # Return list as a string…
013| return ”.join(s)
014|
The above code fragment just generates a short random text string. It’s pretty simple: all uppercase, just letters, and no structure (like spaces or periods or whatnot).
From this starting point, the only limitation is your imagination and interest. The ultimate goal is a random text generator that creates text that looks as close to real text as possible but is strictly random.
The first steps involve using spaces to break the random characters into words and sentences. This requires switching to lowercase and capitalizing the first letter of the first word. It also requires a period at the end of the sentence.
Later steps involve breaking text into paragraphs, adding parenthetical sentences, and making some sentences end with a question or exclamation mark.
One can also tune the random various points to reflect real language. The basic random() function provides a flat distribution. An obvious improvement is selecting letters based on their use in English. Sentence and word lengths can be tuned, too.
§
Without further ado, let’s jump into the code for creating my New Year’s Day blog post.
As is common for me, after some prototyping, I ended up creating a class, named RandomText. The constructor looks like this:
002| ”’New RandomText instance.”’
003| self.size = kwargs[‘paragraphs’] if ‘paragraphs’ in kwargs else 5
004| self.para_min = kwargs[‘para_min’] if ‘para_min’ in kwargs else 1
005| self.para_max = kwargs[‘para_max’] if ‘para_max’ in kwargs else 20
006| self.sent_min = kwargs[‘sent_min’] if ‘sent_min’ in kwargs else 2
007| self.sent_max = kwargs[‘sent_max’] if ‘sent_max’ in kwargs else 17
008| self.word_min = kwargs[‘word_min’] if ‘word_min’ in kwargs else 2
009| self.word_max = kwargs[‘word_max’] if ‘word_max’ in kwargs else 9
010| self.nmbr_min = kwargs[‘nmbr_min’] if ‘nmbr_min’ in kwargs else 1
011| self.nmbr_max = kwargs[‘nmbr_max’] if ‘nmbr_max’ in kwargs else 6
012| self.single_f = kwargs[‘single_f’] if ‘single_f’ in kwargs else 0.01
013| self.number_f = kwargs[‘number_f’] if ‘number_f’ in kwargs else 0.001
014| self.parens_f = kwargs[‘parens_f’] if ‘parens_f’ in kwargs else 0.001
015| self.q_mark_f = kwargs[‘q_mark_f’] if ‘q_mark_f’ in kwargs else 0.1
016| self.exclam_f = kwargs[‘exclam_f’] if ‘exclam_f’ in kwargs else 0.03
017| self.use_freq = kwargs[‘use_freq’] if ‘use_freq’ in kwargs else True
018| self.use_html = kwargs[‘use_html’] if ‘use_html’ in kwargs else False
019| self.use_sect = kwargs[‘use_sect’] if ‘use_sect’ in kwargs else False
020| self.alphas = AlphaSet() if self.use_freq else Alphas
021|
022| # Generate text…
023| ps = [self.paragraph(ix) for ix in range(self.size)]
024| self.text = EOL.join(ps)
025|
A RandomText instance has a lot of keyword parameters, all with defaults. They control various parameters, the minimum and maximum sizes of word, sentences, and paragraphs, for instance.
Down at the bottom (lines 21, 22) a list generator calls paragraph() to create the requested number of paragraphs of random text. The text is assigned to the text member and is available as the str() of the instance.
002| return self.text
003|
One note as we go through this: I put in about a day of work on this with the goal of blog posts just after midnight. So there’s a deadline, is the point, and parts of the code are not as fully developed as intended.
Also, before we continue, here are various important constants:
002| EOL = ‘\n’
003| TAB = ‘\t’
004| SPC = ‘ ‘
005| DOT = ‘.’
006| UCX = ord(‘A’)
007| LCX = ord(‘a’)
008|
009| Alphas = [chr(LCX+n) for n in range(26)]
010| Numbers = [‘0’,‘1’,‘2’,‘3’,‘4’,‘5’,‘6’,‘7’,‘8’,‘9’]
011| Singles = [‘J’, ‘v’, ‘O’, ‘Y’]
012|
§
Here’s the paragraph generator:
002| ”’Return a random paragraph.”’
003| # Determine number of sentences…
004| df = self.para_max – self.para_min
005| ns = int(triangular(self.para_min, self.para_max, df/3))
006|
007| # Generate paragraph sentences…
008| ss = [self.sentence(ix) for ix in range(ns)]
009| # Join sentences into a paragraph…
010| para = SPC.join(ss)
011|
012| # If using HTML…
013| if self.use_html:
014| #TODO: Fix Section use; include bold and center.
015| n = Clip(0, int(gauss(5,2)), 8)
016| s = ‘\xa7\n’ if (self.use_sect and (n < seq)) else ”
017| return ‘<span style=”color: #000000;”>%s</span>%s%s’ % (para, EOL, s)
018|
019| # Else just text; return paragraph (and an EOL)…
020| return ‘%s%s’ % (para, EOL)
021|
This method sets a pattern others will follow. Essentially, it generates a random number using a triangular distribution centered at 1/3 of the range. The idea is bias the random sizes on the smaller side.
The list generator calls sentence() to create the (random) number of sentences.
For purposes of posting on my blog, each paragraph is enclosed in span tags to set the text color to black.
Note that I intended to also have it include the section breaks, but my first pass at it didn’t work, and I left it turned off due to lack of time.
§
Here’s the sentence generator:
002| ”’Return a random sentence.”’
003| # Determine sentence length…
004| df = self.sent_max – self.sent_min
005| nw = int(triangular(self.sent_min, self.sent_max, df/3))
006|
007| # Generate sentence of words…
008| ws = [self.word(ix) for ix in range(nw)]
009|
010| # Occasionally, insert a comma…
011| if (4 <= len(ws)) and (random() < 0.2):
012| ix = Clip(0, int(gauss(len(ws), 2)), len(ws)–2)
013| ws[ix] = ws[ix]+‘,’
014|
015| # Occasionally, use a question or exclamation mark…
016| if random() < self.q_mark_f:
017| e = ‘?’
018| elif random() < self.exclam_f:
019| e = ‘!’
020| else:
021| e = DOT
022|
023| # Join words into a sentence…
024| s = SPC.join(ws)
025|
026| # Occasionally, parenthesize a sentence…
027| if seq and (random() < self.parens_f):
028| return ‘(%s%s)’ % (s, e)
029|
030| # Return sentence…
031| return ‘%s%s’ % (s, e)
032|
It’s pretty much the same sort of thing as the paragraph generator, but has some added complexity to insert occasional commas, and to sometimes use a question or exclamation mark (rather than a period).
It also occasionally wraps a sentence in parenthesis.
The list generator here calls word() to create the sentence.
§
Here’s the word generator:
002| ”’Return a random word. (Capitalize if first in sequence.)”’
003|
004| # Occasionally, return a single-character word…
005| if random() < self.single_f:
006| return choice(Singles)
007|
008| # Occasionally, return a number…
009| if random() < self.number_f:
010| return self.number()
011|
012| # Determine word length…
013| df = self.word_max – self.word_min
014| nc = int(triangular(self.word_min, self.word_max, df*0.42))
015|
016| # Generate word from characters…
017| cs = [self.alpha(seq+ix) for ix in range(nc)]
018|
019| # Join characters and return word…
020| return NUL.join(cs)
021|
The word generator sometimes returns a “single,” a word with just one character. (The default settings set a minimum word-size of two.) The idea is to simulate “I” in English. Note that the generator has multiple singles, whereas English has just the one.
The generator can also sometimes return a random number.
Otherwise, the list generator calls alpha() to create the word.
§
Here are a couple last generators:
002| ”’Return a random character. (Capitalize if first in sequence.)”’
003| # Choose a random character from the set…
004| a = choice(self.alphas)
005|
006| # Return it (capitalize if seq=0…
007| return a if seq else a.upper()
008|
009|
010| def number (self, seq=0):
011| ”’Return a random number.”’
012| # Determine number’s length…
013| nd = randint(self.nmbr_min, self.nmbr_max)
014|
015| # Generate number from random digits…
016| ds = [choice(Numbers) for _ in range(nd)]
017|
018| # Join digits and return number…
019| return NUL.join(ds)
020|
Note that the alpha() generator just returns a random letter, while the number() generator returns a multi-digit number.
§
A key point involves the alpha() generator and its choice() of self.alphas.
That instance member is set in the constructor to be either a simple list of the alphabet, or a generated list about 30000 characters long that contains multiple instances of each letter in amounts that reflect English usage.
This is generated from a frequency table where each letter frequency is multiplied by 30000 to generate a list of that letter.
002|
These are joined together into the alpha list, so a random choice() from the list reflects English letter use.
As an aside, I generated the frequency table by scanning the works of Shakespeare! The resulting frequency table looks like this:
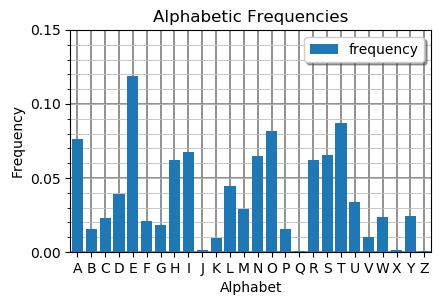
Added together, the frequencies (probabilities) add up to one.
§
Python has a very nice random library that goes far beyond the random() function usually found in a math library. In particular, Python offers different probability distributions — gaussian and triangular, for instance.
I made a chart so I could see for myself:
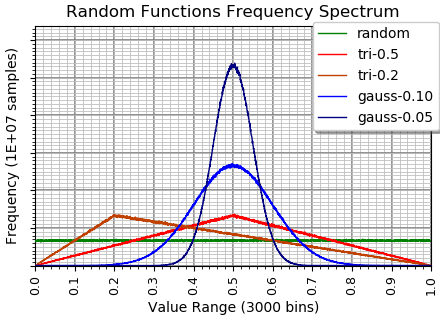
Note how the random() function returns a flat distribution. The triangular distribution is centered on 0.5 and 0.2, respectively. The gaussian distribution is centered on 0.5 with standard deviations of 0.10 and 0.05.
The code for generating the data points looks like this:
002| bins = 3000
003|
004| ys0 = [0]*bins
005| ys1 = [0]*bins
006| ys2 = [0]*bins
007| ys3 = [0]*bins
008| ys4 = [0]*bins
009|
010| for _ in range(samples):
011| n0 = int(random() * bins)
012| n1 = int(triangular(0.0, 1.0, 0.5) * bins)
013| n2 = int(triangular(0.0, 1.0, 0.2) * bins)
014| n3 = int(gauss(0.5, 0.100) * bins)
015| n4 = int(gauss(0.5, 0.050) * bins)
016|
017| ys0[n0] += 1
018| ys1[n1] += 1
019| ys2[n2] += 1
020| ys3[Clip(0,n3,bins–1)] += 1
021| ys4[Clip(0,n4,bins–1)] += 1
022|
This generates histograms of frequency distribution. The gaussian data points can fall outside the range (of 0.0–1.0), so clipping is required to insure a legal index for the histogram bins.
§
All in all, I’m pretty happy with how the blog post turned out.
The only manual changes I made were to insert some section breaks and to italisize some bits to make it more real. Applying italics in the generator is a future improvement.
(Although it’s unlikely I’ll return to this. Not sure why I would.)
Anyway, Happy New Year!!

Is there a way to hide actual words within all the random text?
Easily! That’s what cryptography does, in a sense, although cryptographic functions create the random “text.”
In this case, there was just random text, but one could then impose a text stream in any of a variety of ways. Every second letter of every third word, or whatever. In general the process is called steganography, and its applications are fascinating!
Pingback: Python Generators, part 3 | The Hard-Core Coder
Pingback: The Playfair Cipher | The Hard-Core Coder
Pingback: Friday Notes (Nov 21, 2025) | Logos con carne