
Tags
computer, computer code, computer programming, computer science, Python code, state engine, state table
At one point in my career, the state engine (SE) was one of my favorite AWK hammers. At the time much of the work involved text processing or, in some cases, serial byte processing (which is not quite the same thing). That sort of thing is right in the wheelhouse for a state engine.
They are a very useful tool and an important part of any programmer’s toolkit.
Over that period of years I was freely wielding my AWK hammer, part of the fun was converging on a reusable SE framework I could use to implement new applications quickly and painlessly.
One challenge is that the input stream (which drives the process) can differ considerably in data type. Object-oriented languages make that part much easier, as you can design around a base type.
Another challenge is an easy way to create the state transition table. Again, some languages make that easier, others harder. (A lot of my work was in C back then, and one characteristic of state tables is the need to forward reference. In C, that means lots of #defines or enum lists.)
 But for those who may be new to state engines and state tables, I should back up a bit. A state engine is an algorithm that’s driven by some sort of serial input stream. Each item in the input stream causes a state change in the engine.
But for those who may be new to state engines and state tables, I should back up a bit. A state engine is an algorithm that’s driven by some sort of serial input stream. Each item in the input stream causes a state change in the engine.
Those changes are governed by a state (transition) table that describes how to move from state to state. Each item in the table has four essential items:
- The name of the current state.
- A possible input item (or list of items).
- The name of the next state.
- A task to perform.
For each input item, the engine searches the table for a match on the first two items: The current state and the current input item. If it finds a match, it performs the task and changes to the state specified.
That’s it. That’s all the engine does. The logic is all in the state table. Which can have many dozens, even hundreds, of items. A complex state table, which very hard to manage, can accomplish complex tasks.
 But even simple ones have multiple items that match each state and multiple items that “point” to each state.
But even simple ones have multiple items that match each state and multiple items that “point” to each state.
But there can only be one item with a given input item for any given state.
One way to think of it is that the input items are “tickets” out of the state. What’s on the ticket determines which exit you take.
In a very real sense, a state engine and its table are the very incarnation of a Turing Machine. (My attempt to find a SE framework was a search of a UTM.)
They’re not so useful in an event-driven architecture, but they’re great at parsing text or processing serial data streams. They become less useful as the number of tokens necessary for semantics rises.
One last general comment: You can detect errors — unexpected or illegal values — in the input stream one of two ways: They can be accounted for by items in the table, in which case the next state is usually NULL and the task is throwing an exception. Or they can be left out of the table, in which case the engine can’t find a matching item and throws a general exception.
§
Back in the Little Programming Languages post, I introduced a simple language where every expression has this form:
[name:]keyword(description)
Here is a state diagram that parses that syntax:
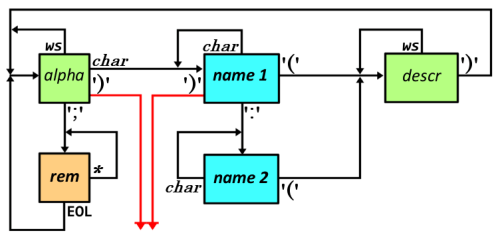
As with all state engines, there is an initial starting state (alpha). Various combinations of conditions return to that state, so it can be re-visited.
The diagram is a little misleading in that the implementation won’t actually have a description (descr) state. A move to that state (from name-1 or name-2) is actually a recursion.
Note that the (virtual) descr state has a single exit condition: the close parenthesis. In the recursion, that’s actually a return to the calling level. On the diagram it’s shown as the two red transitions (both of which are conditional on the close parenthesis).
A few other things to know: char matches any valid name character, ws matches whitespace (which in this system includes commas!), EOL matches end-of-line, and * matches (as you might expect) anything.
I’ve said the engine is simple. Here it is (in Python):
def parse_source_text (source_text):
src = SourceReader(source_text)
state = 'alpha'
src.StartSource()
c = src.cc()
while len(c):
ss = StateTable[state]
for test,nxt,ftn in ss:
if test(c):
if ftn:
src.__getattribute__(ftn)()
state = nxt
break
c = src.nc()
src.EndSource()
return src
That should be pretty easy to understand. The hardest part for non-Python programmers (or beginners, even) is probably the __getattribute__ part.
It’s also apparent that a SourceReader object plays a big role here (huge, in fact) and that StateTable factors in as well (it’s obviously the table of state transitions).
The StateTable is a Python dict (associate array) where the key is the name (a string) of a state and each item is a list of tuples. Each tuple has the format:
( condition-function, state-name, task-name )
The condition-function is a function that takes a character and returns True or False.
The state-name is the name (a string) of a state to move to. (It can be the name of the current state if the condition causes the engine to stay in that state.) The name here matches the table key names.
The task-name is the name (a string) of a method in the SourceReader class.
That class, SourceReader, has all the methods that implement what’s actually done with the input. All the code related to that goes in these methods. (As you saw, the engine is very simple and knows nothing about the input.)
The class also provides methods related to the text being parsed, in particular the nc() and cc() methods (next character and current character, respectively).
The class could (and really should) also contain the StateTable. In some applications it’s especially nice to let the part that knows about the input also have some leverage on selecting states that match. In such cases, rather than the engine directly accessing StateTable, it can use a method .FindState(state, char).
In order to de-couple the state table from the SourceReader class, the table uses method names (strings). That’s what the (built-in Python) __getattribute__(name) function does, it takes a name and returns an object’s attribute. In this case, the method object.
The engine invokes that returned method object (the trailing parentheses). That’s how the engine performs the task each transition specifies. The task-name is allowed to be None, which signals no task.
That’s enough for this time. Next time I’ll get into more detail about that SourceReader class. For now, here’s the StateTable (see if you can spot the slight difference between the state table this actually implements and the diagram show earlier).
StateTable = {
'alpha':[
(IsWS , 'alpha' , None),
(IsChar(';'), 'comment' , None),
(IsChar(')'), 'alpha' , 'ExitDescr'),
(IsName , 'name1' , 'StartName1'),
(IsAny , 'ERROR' , 'Error'),
],
'comment':[
(IsNL , 'alpha' , None),
(IsAny , 'comment' , None),
],
'name1':[
(IsWord , 'name1' , 'AddToName1'),
(IsChar(':'), 'name2' , 'StartAction'),
(IsChar('('), 'alpha' , 'StartObject'),
(IsChar(')'), 'alpha' , 'ExitDescr'),
(IsWS , 'alpha' , 'EndReference'),
(IsAny , 'ERROR' , 'Error'),
],
'name2':[
(IsName , 'name3' , 'StartName2'),
(IsSPC , 'name2' , None),
(IsAny , 'ERROR' , 'Error'),
],
'name3':[
(IsWord , 'name3' , 'AddToName2'),
(IsChar(' '), 'name2' , None),
(IsChar('('), 'alpha' , 'StartObject'),
(IsAny , 'ERROR' , 'Error'),
],
}
It’s a dictionary of states. Each state is a list of next-state tuples containing three elements: A key that must be matched, the name of the next state, and the function to execute.

Pingback: Full Adder Code | The Hard-Core Coder
Pingback: Building a Turing Machine | The Hard-Core Coder